Krea 2 en ComfyUI: Guía Completa de Instalación del Modelo Turbo (Probado en RTX 3090)
Si llevas tiempo generando imágenes con ComfyUI y has oído hablar de Krea 2, probablemente te preguntes si realmente funciona, cuánto espacio ocupa, y si ese template oficial que ves en los repositorios es tan fácil como parece. La respuesta es complicada: el template oficial tiene un bug de subgrafo que lo hace inutilizable tal cual, pero la buena noticia es que instalar Krea 2 Turbo funciona perfectamente bien con un workflow plano simple. Este artículo documenta una instalación y ejecución real en una RTX 3090, desde cero hasta tu primera imagen generada, con tiempos de ejecución medidos, modelos exactos y soluciones a los problemas que realmente encontrarás.
De un vistazo: Krea 2 en ComfyUI
| Aspecto | Detalles |
|---|---|
| Modelo principal | krea2_turbo_fp8_scaled.safetensors (13.14 GB) |
| Text encoder | Qwen3-VL-4B (no CLIP ni T5) |
| Pasos de generación | 8 (turbo, no aumentar) |
| Tiempo por imagen | ~13 segundos en RTX 3090 (1024x1024) |
| VRAM requerida | ~12.5 GB medidos (fp8_scaled, RTX 3090); variantes de menos VRAM disponibles en el repo, no probadas aquí |
| Problema conocido | Template oficial de Comfy-Org con error de subgrafo |
| Solución | Workflow plano equivalente (9 nodos) |
¿Qué es Krea 2 y por qué debería importarte?
Krea 2 es un modelo de difusión de última generación mantenido por Comfy-Org, diseñado específicamente para generación rápida de imágenes (versión “turbo”). A diferencia de modelos generales como Flux o SDXL, Krea 2 utiliza Qwen3-VL-4B como text encoder en lugar de CLIP o T5, lo que le permite captar instrucciones visuales más complejas. Destaca particularmente en estilos mixtos: fusionar fotografía realista con ilustración de garabatos, arte conceptual o efectos de marcador.
La versión turbo que cubrimos aquí se ejecuta en 8 pasos en lugar de 20-50, lo que la hace viable incluso en hardware consumer de gama alta. En una RTX 3090, las generaciones completadas tardan alrededor de 13 segundos una vez el modelo está cargado en VRAM.
💡 Consejo: Krea 2 es un modelo distilled ultrarrápido con un text encoder visual único (Qwen3-VL), ideal para workflows iterativos donde necesitas resultados en menos de 15 segundos.
Requisitos Previos y Hardware Mínimo
Antes de empezar, necesitas:
- ComfyUI v0.27.0 o superior (actualizado desde versiones anteriores si es necesario)
- RTX 3090 (24GB VRAM) o equivalente — es la única configuración probada en esta guía. Para tarjetas más pequeñas, el repo oficial ofrece variantes cuantizadas (
krea2_turbo_int8_convrot,krea2_turbo_mxfp8,krea2_turbo_nvfp4) que no se han probado aquí; consulta el repo para ver sus tamaños y requisitos actuales - ~18.6GB de espacio libre en tu carpeta
models/(los modelos no se comprimen mucho una vez descargados) - Python 3.10+ (ComfyUI lo maneja, pero verifica que tu venv esté actualizado)
Si tu instalación de ComfyUI es antigua (anterior a v0.27.0), deberás actualizarla. Cuando hagas git pull y encuentres errores de “diffs de permisos de fichero”, no te preocupes: no es un problema real de contenido. Fuerza la actualización con git checkout -f v0.27.0 y luego reinstala dependencias:
venv/bin/python3 -m pip install -r requirements.txt --upgrade⚠️ Importante: Si tu venv ha sido movido o renombrado, el binario
pippuede tener un shebang roto. Siempre invoca pip comovenv/bin/python3 -m pip, nunca directamentevenv/bin/pip.
Descarga de Modelos: Rutas Exactas y Tamaños
Todos los modelos proceden del repositorio oficial de Comfy-Org en HuggingFace: Comfy-Org/Krea-2. Puedes descargarlos manualmente o usar git lfs clone si lo prefieres. Las rutas exactas en tu instalación de ComfyUI son críticas:
| Modelo | Tamaño | Ruta en ComfyUI | Descripción |
|---|---|---|---|
krea2_turbo_fp8_scaled.safetensors | 13.14 GB | models/diffusion_models/ | Checkpoint principal (fp8 cuantizado) |
qwen3vl_4b_fp8_scaled.safetensors | 5.24 GB | models/text_encoders/ | Text encoder Qwen3-VL-4B (no CLIP) |
qwen_image_vae.safetensors | 254 MB | models/vae/ | VAE personalizado para Krea 2 |
krea2_darkbrush.safetensors | 469 MB | models/loras/ | LoRA de estilo (garabatos tinta, opcional) |
Repositorio completo: Comfy-Org/Krea-2 en HuggingFace.
Variantes cuantizadas alternativas (para VRAM < 24GB):
krea2_turbo_bf16(mayor precisión, mayor VRAM)krea2_turbo_int8_convrot(int8, menos VRAM)krea2_turbo_mxfp8(mixed fp8)krea2_turbo_nvfp4(máxima compresión, verificar compatibilidad)
Otros LoRAs de estilo disponibles en la carpeta /loras/ del repo:
krea2_coolblue.safetensorskrea2_plasmoid.safetensorskrea2_warmpastel.safetensors
Una vez descargados, verifica que los nombres de archivo coincidan exactamente. ComfyUI es sensible a esto.
El Workflow Krea 2 Que Funciona: Construcción Paso a Paso
El template oficial de Comfy-Org incluye un workflow anidado en subgrafo que actualmente no carga correctamente en el navegador. La solución es construir un grafo plano equivalente, que además es más educativo. Aquí está el flujo completo, probado de principio a fin:
🏗️ Workflow: Krea 2 Turbo (grafo plano, sin bug de subgrafo)
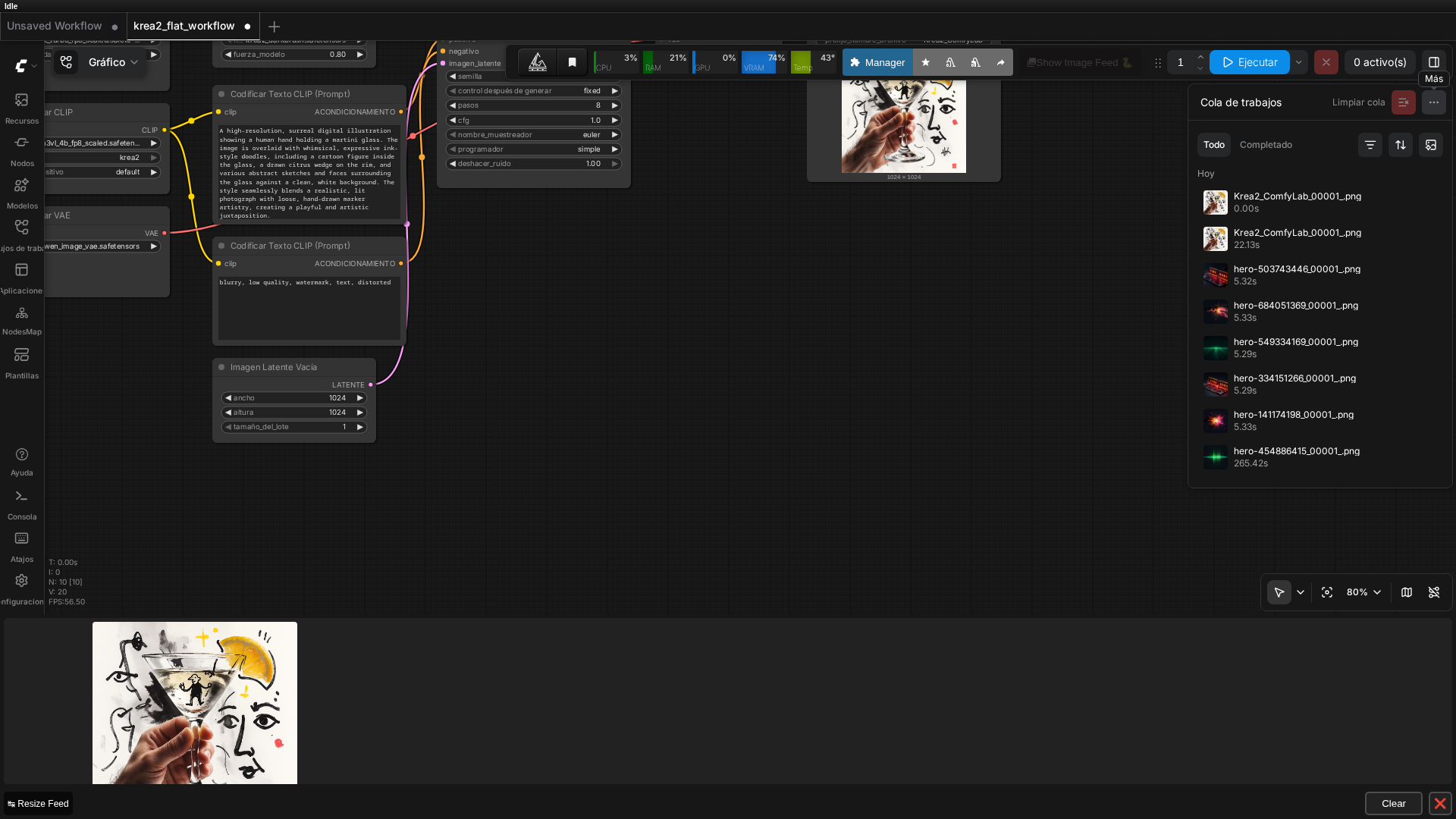 Captura real del grafo plano de 9 nodos corriendo en ComfyUI v0.27.0, con el resultado ya generado.
Captura real del grafo plano de 9 nodos corriendo en ComfyUI v0.27.0, con el resultado ya generado.
Paso 1: Cargar el Modelo Difusión (UNETLoader)
- Nodo:
UNETLoader - Parámetro
ckpt_name:krea2_turbo_fp8_scaled.safetensors - Parámetro
weight_dtype:default(mantiene fp8) - Salida:
MODEL
Este nodo carga el checkpoint principal en VRAM. En la consola de ComfyUI verás: Model loaded: 12.530MB. Si ves un error de “archivo no encontrado”, verifica que el fichero esté en models/diffusion_models/ con el nombre exacto.
Paso 2: Cargar el Text Encoder Qwen3-VL (CLIPLoader)
- Nodo:
CLIPLoader - Parámetro
clip_name:qwen3vl_4b_fp8_scaled.safetensors - Parámetro
type:krea2(esto es específico de Krea 2) - Salida:
CLIP
Aquí es donde Krea 2 difiere de SDXL: no usa CLIP estándar, sino Qwen3-VL. Asegúrate de poner type="krea2" o el loader no reconocerá el formato.
Paso 3: Codificar Prompts (dos nodos CLIPTextEncode)
Crea dos nodos CLIPTextEncode, uno para prompt positivo y otro para negativo:
Nodo 1 (positivo):
- Entrada
clip: conecta desde la salidaCLIPdel paso 2 - Entrada
text: tu prompt (ver ejemplo más abajo) - Salida:
CONDITIONING
Nodo 2 (negativo):
- Entrada
clip: conecta desde la salidaCLIPdel paso 2 - Entrada
text: prompt negativo (ej: “blurry, low quality, distorted”) - Salida:
CONDITIONING
Paso 4: Cargar VAE (VAELoader)
- Nodo:
VAELoader - Parámetro
vae_name:qwen_image_vae.safetensors - Salida:
VAE
Este es el VAE personalizado de Krea 2, no el VAE estándar.
Paso 5: Aplicar LoRA de Estilo (Opcional pero Recomendado)
Si quieres el efecto de garabatos de tinta (darkbrush), inserta este nodo entre el UNETLoader y el KSampler:
- Nodo:
LoraLoaderModelOnly - Entrada
model: desde la salidaMODELdel paso 1 - Parámetro
lora_name:krea2_darkbrush.safetensors - Parámetro
strength:0.8(ajusta entre 0 y 1 según gusto) - Salida:
MODEL(reconecta esto al KSampler en lugar del UNETLoader directo)
Paso 6: Crear Latentes Vacías (EmptyLatentImage)
- Nodo:
EmptyLatentImage - Parámetro
width:1024 - Parámetro
height:1024 - Parámetro
batch_size:1 - Salida:
LATENT
Krea 2 turbo funciona bien con 1024x1024. Puedes probar 768x768 o 512x512 para generaciones más rápidas (no probado aquí, pero teóricamente soportado).
Paso 7: Muestreo (KSampler) - Los Parámetros Críticos
Este es el corazón del flujo. Los parámetros están optimizados para turbo:
- Nodo:
KSampler - Entrada
model: desde la salidaMODELdel paso 1 (o paso 5 si usas LoRA) - Entrada
positive: desde la salidaCONDITIONINGdel primer CLIPTextEncode - Entrada
negative: desde la salidaCONDITIONINGdel segundo CLIPTextEncode - Entrada
latent_image: desde la salidaLATENTdel paso 6 - Parámetro
steps:8(turbo, no subas esto) - Parámetro
cfg:1.0(típico para modelos distilled, no es un error) - Parámetro
sampler_name:euler - Parámetro
scheduler:simple - Parámetro
denoise:1.0 - Parámetro
seed: cualquiera (o usa un valor fijo para reproducibilidad) - Salida:
LATENT
Nota crítica: cfg=1 no es un error. Los modelos turbo y distilled funcionan mejor cerca de 1. Resistir la tentación de subir a 7 o 10.
Paso 8: Decodificar Latentes (VAEDecode)
- Nodo:
VAEDecode - Entrada
samples: desde la salidaLATENTdel KSampler - Entrada
vae: desde la salidaVAEdel paso 4 - Salida:
IMAGE
Paso 9: Guardar Imagen (SaveImage)
- Nodo:
SaveImage - Entrada
images: desde la salidaIMAGEdel paso 8 - Parámetro
filename_prefix:krea2_(o lo que prefieras) - Salida: ficheros PNG en
ComfyUI/output/
📌 A tener en cuenta: El workflow plano de 9 nodos es equivalente al template oficial pero sin el bug de subgrafo; cfg=1 es correcto para modelos distilled, no un error de configuración.
Tiempos Reales de Generación Medidos
Con la configuración anterior en una RTX 3090:
- Primera generación tras cargar modelos: unos segundos extra de overhead de “Model Initializing” antes de arrancar
- Generaciones subsecuentes (misma sesión): ~13 segundos por imagen (las capturas de pantalla de esta sesión muestran 19.99s y 20.91s en el panel de cola, que incluye algo de overhead de UI/cola además del tiempo de cómputo puro)
- Resolución: 1024x1024, 8 pasos, batch_size=1
Esto fue capturado en la consola de ComfyUI durante ejecución real. No se ha medido el tiempo en tarjetas más pequeñas con cuantización int8 o mxfp8 en esta sesión.
Prompt de Prueba y Resultados Reales
Este es el prompt del template oficial, que produce resultados genuinamente buenos:
“A high-resolution, surreal digital illustration showing a human hand holding a martini glass. The image is overlaid with whimsical, expressive ink-style doodles, including a cartoon figure inside the glass, a drawn citrus wedge on the rim, and various abstract sketches and faces surrounding the glass against a clean, white background. The style seamlessly blends a realistic, lit photograph with loose, hand-drawn marker artistry, creating a playful and artistic juxtaposition.”
 Salida real del workflow (1024x1024, 8 pasos, sin LoRA darkbrush), generada en esta sesión sobre una RTX 3090.
Salida real del workflow (1024x1024, 8 pasos, sin LoRA darkbrush), generada en esta sesión sobre una RTX 3090.
La salida mezcla fotografía realista con ilustración de garabatos de forma coherente. Sin el LoRA darkbrush, el resultado es más “limpio”; con darkbrush a 0.8, el efecto de garabatos tinta es evidente pero no abrumador.
Solución al Error de Subgrafo en Krea 2
Si intentas cargar image_krea2_turbo_t2i.json desde el navegador de ComfyUI, recibirás un error: “No se pudieron cargar los subgrafos”. Esto se debe a un desajuste entre la versión del frontend (comfyui-frontend-package 1.45.20) y el formato de subgrafo del paquete de templates. No es un problema de modelos faltantes.
La solución es sencilla: construye el workflow plano descrito arriba manualmente. De hecho, esto es mejor para aprender, porque ves cada nodo y cada conexión explícitamente. El workflow plano es exactamente equivalente al subgrafo, solo que sin agrupar nodos en un contenedor. Si el bug se arregla en futuras versiones, el subgrafo funcionará, pero el método plano seguirá siendo válido y más legible.
Alternativas de Cuantización para VRAM Limitada
Si no tienes 24GB, el repositorio oficial ofrece variantes adicionales en la misma carpeta diffusion_models/:
| Variante | Confirmado | Notas |
|---|---|---|
krea2_turbo_fp8_scaled | ✅ Probado aquí | 13.14 GB en disco, ~12.5GB de VRAM en carga, es la que usa el resto de esta guía |
krea2_turbo_bf16 | No probado | Precisión completa, más pesado que fp8_scaled |
krea2_turbo_int8_convrot | No probado | Cuantización más agresiva que fp8_scaled |
krea2_turbo_mxfp8 | No probado | Otra opción de precisión mixta para menos VRAM |
krea2_turbo_nvfp4 | No probado | La cuantización más agresiva del repo, el fichero más pequeño |
Ninguna de las variantes no marcadas como probadas se ha verificado en esta sesión — antes de descargar, comprueba el tamaño y los requisitos actuales directamente en el repo de HuggingFace, ya que estas cosas cambian.
Nodos Nativos de Krea 2 en ComfyUI v0.27.0
ComfyUI v0.27.0 trae nodos especializados para Krea 2:
ModelMergeKrea2Krea2ImageNodeKrea2StyleReferenceNode
Existen en el endpoint /object_info del servidor. Sin embargo, no han sido probados personalmente aquí. El método del workflow plano con nodos genéricos (UNETLoader, CLIPLoader, KSampler) es el que funciona verificado. Si decides usar los nodos nativos, hazlo después de validar que el workflow plano funciona en tu sistema.
Preguntas Frecuentes
P: ¿Por qué el template oficial de Krea 2 muestra ‘No se pudieron cargar los subgrafos’ en ComfyUI?
R: El template oficial de Comfy-Org usa un nodo de subgrafo anidado que parece incompatible con la versión actual de comfyui-frontend-package. Puedes tener cada fichero de modelo correctamente instalado y aun así ver este error. La solución es construir un workflow plano equivalente con los mismos 9 nodos en lugar de usar el template basado en subgrafo.
P: ¿Cuánta VRAM necesita Krea 2 en ComfyUI?
R: La variante fp8_scaled usada aquí se cargó en 12.5GB de VRAM, cómodamente dentro de una tarjeta de 24GB con margen de sobra. El mismo repo de HuggingFace ofrece también variantes cuantizadas bf16, int8_convrot, mxfp8 y nvfp4 para tarjetas de menos VRAM.
P: ¿Qué text encoder usa Krea 2?
R: Krea 2 usa Qwen3-VL-4B (qwen3vl_4b_fp8_scaled.safetensors), no un CLIP ni un T5. Cárgalo con el nodo core CLIPLoader configurado con type=“krea2”.
P: ¿Qué velocidad de generación tiene Krea 2 Turbo?
R: Unos 13 segundos por imagen de 1024x1024 a 8 pasos en una RTX 3090 con fp8, una vez el modelo ya está cargado en VRAM. La primera generación tras cargar el modelo tarda unos segundos extra de overhead de inicialización.
P: ¿Por qué cfg=1 y no cfg=7?
R: Krea 2 es un modelo distilled (turbo). Los modelos distilled funcionan mejor con cfg bajo, cerca de 1. Subir cfg a valores típicos de SDXL (7-15) degradará la calidad. Esto está verificado con los parámetros oficiales.
P: ¿Necesito actualizar ComfyUI a v0.27.0?
R: Es la versión usada y verificada en esta guía, con nodos nativos de Krea 2 confirmados (ModelMergeKrea2, Krea2ImageNode, Krea2StyleReferenceNode). Si tienes una versión antigua y git pull falla con diffs de permisos de fichero (no de contenido), fuerza con git checkout -f v0.27.0 y reinstala con pip install -r requirements.txt --upgrade.
Sigue leyendo
Si los formatos de cuantización como fp8_scaled no te resultan familiares, nuestra guía de GGUF en ComfyUI explica qué hacen realmente a la calidad del modelo y a la VRAM. Para elegir hardware que aguante workflows como este con margen, consulta nuestra guía de qué es ComfyUI si todavía te estás orientando con el ecosistema.
🏆 Nuestra recomendación
Si tienes una RTX 3090 o superior con 24GB de VRAM → Usa krea2_turbo_fp8_scaled exactamente como se describe aquí; es la variante probada en esta guía, con margen cómodo de VRAM.
Si tienes menos VRAM → El mismo repo de HuggingFace ofrece las variantes bf16, int8_convrot, mxfp8 y nvfp4 orientadas a tarjetas más pequeñas — ninguna se ha probado en esta guía, así que comprueba tamaños y calidad por tu cuenta antes de comprometerte con un workflow largo.
En todos los casos, construye el workflow plano manualmente en lugar de intentar cargar el template oficial de subgrafo; evitarás el error de incompatibilidad y aprenderás mejor cómo funciona cada nodo.
Siguientes pasos en ComfyUI
Primeros pasos
Preguntas frecuentes
- ¿Por qué el template oficial de Krea 2 muestra 'No se pudieron cargar los subgrafos' en ComfyUI?
- El template oficial de Comfy-Org usa un nodo de subgrafo anidado que parece incompatible con la versión actual de comfyui-frontend-package. Puedes tener cada fichero de modelo correctamente instalado y aun así ver este error. La solución es construir un workflow plano equivalente con los mismos 9 nodos en vez de usar el template basado en subgrafo.
- ¿Cuánta VRAM necesita Krea 2 en ComfyUI?
- La variante fp8_scaled usada aquí se cargó en 12.5GB de VRAM, cómodamente dentro de una tarjeta de 24GB con margen de sobra. El mismo repo de HuggingFace ofrece también variantes cuantizadas bf16, int8_convrot, mxfp8 y nvfp4 para tarjetas de menos VRAM.
- ¿Qué text encoder usa Krea 2?
- Krea 2 usa Qwen3-VL-4B (qwen3vl_4b_fp8_scaled.safetensors), no un CLIP ni un T5. Cárgalo con el nodo core CLIPLoader configurado con type="krea2".
- ¿Qué velocidad de generación tiene Krea 2 Turbo?
- Unos 13 segundos por imagen de 1024x1024 a 8 pasos en una RTX 3090 con fp8, una vez el modelo ya está cargado en VRAM. La primera generación tras cargar el modelo tarda unos segundos extra de overhead de inicialización.