El error torch.cuda.OutOfMemoryError: CUDA out of memory es el más frecuente en ComfyUI para usuarios con GPUs de 4GB, 6GB y 8GB de VRAM. Aparece cuando el modelo, la resolución o el proceso de generación necesitan más memoria de vídeo de la que tiene disponible tu tarjeta gráfica.
La buena noticia: tiene solución en casi todos los casos. Este artículo te explica las causas exactas y las soluciones ordenadas de más inmediata a más definitiva.
Si el error aparece de repente en un workflow que antes funcionaba, empieza por reiniciar ComfyUI completamente. La VRAM se fragmenta en sesiones largas y un reinicio limpio suele bastar.
Captura real del error
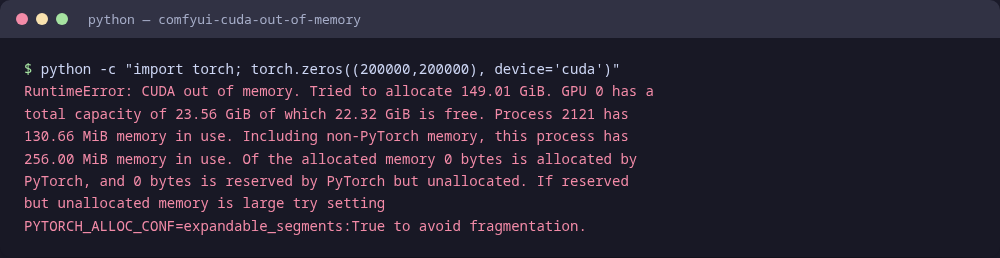 Un CUDA out of memory real, reproducido y capturado en una RTX 3090
Un CUDA out of memory real, reproducido y capturado en una RTX 3090
Por qué ocurre el error CUDA out of memory
La VRAM (memoria de la GPU) tiene que alojar simultáneamente:
- El modelo de difusión (checkpoint, UNET o GGUF)
- El text encoder (CLIP, T5XXL u otro)
- El VAE para decodificar los latents
- El buffer de latents durante el sampling
- El framebuffer de la imagen final
Con un modelo SDXL completo (6-7GB), un VAE (800MB) y el proceso de sampling, una GPU de 8GB se queda justa. Con Flux Dev completo (12-16GB), es imposible sin optimizaciones en cualquier consumidor de gama media.
El error puede aparecer en tres momentos distintos:
- Al cargar el modelo — el checkpoint no cabe en VRAM
- Durante el KSampler — la resolución o el batch size superan la memoria disponible
- En el VAEDecode — el paso final de decodificación falla aunque el sampling haya ido bien
Solución 1: Reiniciar ComfyUI (2 minutos)
Antes de tocar nada más, cierra ComfyUI completamente y vuelve a abrirlo. No solo recarga la página; detén el proceso Python.
En Windows:
Ctrl+C en la terminal → volver a ejecutar python main.pyEn Linux/Mac:
# Ctrl+C en la terminal o:
pkill -f "python main.py"
python main.pyLa VRAM fragmentada acumula residuos de modelos anteriores que no se liberan automáticamente. Un reinicio limpio recupera varios GB en sesiones largas.
Solución 2: Flags de memoria al arrancar ComfyUI
ComfyUI incluye flags específicos para GPUs con poca VRAM. Añádelos al comando de arranque según tu situación:
| Flag | Cuándo usarlo | Efecto |
|---|---|---|
--lowvram | GPUs de 4-6GB | Descarga partes del modelo a RAM cuando la VRAM se llena. Más lento pero funciona. |
--medvram | GPUs de 6-8GB | Balance entre velocidad y consumo de memoria. |
--novram | Casos extremos / 4GB | Todo a RAM. Muy lento pero permite generar en GPUs mínimas. |
--cpu | Sin GPU dedicada | Usa solo CPU. Extremadamente lento, solo para pruebas. |
Ejemplo en Windows:
python main.py --lowvramEjemplo en Linux:
python main.py --medvramNo combines --lowvram y --medvram en el mismo comando. Usa solo uno según tu VRAM disponible.
Si usas el launcher de ComfyUI Desktop, ve a Settings → Extra launch flags y añade el flag correspondiente.
Solución 3: Reducir la resolución
La VRAM que consume el proceso de sampling escala cuadráticamente con la resolución. Pasar de 1024px a 768px puede reducir el consumo de memoria a la mitad.
Referencia por modelo y GPU:
| Modelo | 4GB VRAM | 6GB VRAM | 8GB VRAM |
|---|---|---|---|
| SD 1.5 | 512×512 ✅ | 768×768 ✅ | 1024×1024 ✅ |
| SDXL | ❌ sin flags | 768×768 con --lowvram | 1024×1024 con --medvram |
| Flux GGUF Q4 | 512×512 con --lowvram | 768×768 ✅ | 1024×1024 ✅ |
| Flux Dev completo | ❌ | ❌ | ❌ sin optimizaciones |
En el nodo Empty Latent Image, baja width y height al siguiente escalón. SD 1.5 y SDXL trabajan mejor en múltiplos de 64. Flux necesita múltiplos de 16.
Si necesitas imagen final grande, genera pequeño y usa un workflow de upscaling posterior: menos VRAM durante la generación, misma calidad de salida. Consulta la guía de upscaling 4K en ComfyUI.
Solución 4: Activar tiled VAE
El VAEDecode es el paso que convierte los latents en imagen final y consume una cantidad fija de VRAM independientemente del sampling. En resoluciones altas puede ser el único responsable del OOM aunque el KSampler haya funcionado bien.
Activar VAE tiling en ComfyUI:
- En el nodo
VAEDecode, activa la opcióntile_sizesi tu versión la incluye. - Alternativamente, instala el nodo
VAEDecodeTileddesde ComfyUI Manager. - Sustituye tu
VAEDecodeactual porVAEDecodeTiledy conecta las mismas entradas.
El tiling divide la imagen en bloques y los decodifica por partes, reduciendo el pico de VRAM al coste de un tiempo de procesado ligeramente mayor.
En resoluciones ≤768px no notarás diferencia de velocidad. A partir de 1024px el tiled VAE puede ser la diferencia entre OOM y generación exitosa.
Solución 5: Usar modelos GGUF cuantizados
Esta es la solución definitiva para GPUs con poca VRAM. Los modelos GGUF son versiones cuantizadas que reducen el tamaño del modelo a costa de una pérdida de calidad mínima o imperceptible.
Comparativa de Flux Dev:
| Versión | Tamaño | VRAM necesaria | Calidad |
|---|---|---|---|
| Flux Dev completo (bf16) | 24GB | 24GB+ | Referencia |
| Flux Dev fp8 | 12GB | 12GB | ≈99% |
| Flux Dev GGUF Q8_0 | 12GB | 8-10GB | ≈98% |
| Flux Dev GGUF Q4_K_M | 7GB | 6-8GB | ≈95% |
| Flux Dev GGUF Q3_K_M | 5.5GB | 5-6GB | ≈90% |
Para cargar modelos GGUF en ComfyUI necesitas el nodo UnetLoaderGGUF del paquete ComfyUI-GGUF, instalable desde ComfyUI Manager.
Los text encoders también se pueden cuantizar:
t5xxl_fp16.safetensors(9GB) →t5xxl_fp8_e4m3fn.safetensors(4.5GB)clip_l.safetensors(246MB) → sin cambios, ya es pequeño
Solución 6: Actualizar drivers NVIDIA (modelos 2025-2026)
Si el OOM aparece específicamente con Flux.2, LTX 2.3 o modelos publicados en 2025-2026, puede ser un problema de driver, no de VRAM.
A partir de abril 2026, estos modelos requieren NVIDIA Studio Driver 595 o superior. Los drivers anteriores crashean con arquitecturas nuevas aunque la VRAM sea suficiente.
Descarga el Studio Driver (no el Game Ready) desde la web oficial de NVIDIA y reinstala PyTorch para la versión CUDA correspondiente:
# Verificar versión CUDA instalada
nvcc --version
# Reinstalar PyTorch (ejemplo CUDA 12.4)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124Diagnóstico rápido: ¿en qué paso falla?
El error aparece al cargar el modelo:
→ El checkpoint no cabe en VRAM. Usa --lowvram o cambia a versión GGUF cuantizada.
El error aparece en el KSampler:
→ La resolución o el batch size son demasiado altos. Baja la resolución o reduce batch_size a 1.
El error aparece en el VAEDecode:
→ Activa VAE tiling o usa un VAE cuantizado (ae-fp8.safetensors para Flux).
El error aparece de forma aleatoria en workflows que antes funcionaban: → VRAM fragmentada. Reinicia ComfyUI.
El error aparece solo con modelos publicados en 2025-2026: → Actualiza drivers NVIDIA al Studio Driver 595+.
Configuración recomendada por GPU
GPU de 4GB VRAM (GTX 1650, RTX 3050 4GB)
python main.py --lowvram- Modelo: SD 1.5 o Flux GGUF Q3_K_M
- Resolución máxima: 512×512 (SD 1.5), 640×640 (Flux GGUF)
- VAE tiling: activar siempre
GPU de 6GB VRAM (RTX 3060 6GB, RTX 4060 8GB con restricciones)
python main.py --medvram- Modelo: SDXL con
--lowvramo Flux GGUF Q4_K_M - Resolución máxima: 768×768
- VAE tiling: recomendado a partir de 768px
GPU de 8GB VRAM (RTX 3070, RTX 4060 Ti)
python main.py --medvram- Modelo: SDXL, Flux GGUF Q8_0
- Resolución máxima: 1024×1024
- VAE tiling: solo necesario con Flux a 1024px+
GPU de 12GB VRAM (RTX 3060 12GB, RTX 4070)
- Sin flags de memoria necesarios para la mayoría de modelos
- Flux Dev fp8 funciona cómodamente
- Resolución máxima: 1024×1024 sin problemas, 1280×1280 con tiling
Troubleshooting adicional
El flag —lowvram va demasiado lento:
Prueba --medvram primero. Si da OOM, vuelve a --lowvram. La diferencia de velocidad entre ambos depende mucho del modelo y la resolución.
Tengo 12GB de VRAM y aun así aparece OOM:
Comprueba que no tienes otros programas usando la GPU (juegos, monitores de GPU, otra instancia de ComfyUI). Usa nvidia-smi en terminal para ver qué proceso ocupa VRAM.
El error desaparece y vuelve a aparecer de forma aleatoria: Casi siempre es fragmentación de VRAM. Reinicia ComfyUI cada pocas horas de uso intensivo.
Tengo RAM abundante pero poca VRAM:
Los flags --lowvram y --novram aprovechan la RAM del sistema. Con 16GB+ de RAM y --lowvram puedes correr modelos que no cabrían en VRAM a costa de velocidad.
Si después de aplicar todas estas soluciones sigues con OOM en modelos específicos, consulta la guía de optimización de ComfyUI para poca VRAM para ajustes más avanzados.
Siguientes pasos en ComfyUI
Primeros pasos
Preguntas frecuentes
- ¿Por qué aparece CUDA out of memory en ComfyUI?
- Porque el modelo, la resolución o el batch size superan la VRAM disponible en tu GPU. Con GPUs de 4-8GB es muy común al intentar usar modelos SDXL o Flux sin optimizaciones.
- ¿Funciona --lowvram con cualquier GPU NVIDIA?
- Sí. El flag --lowvram hace que ComfyUI descargue partes del modelo a RAM cuando la VRAM se llena. Es más lento pero permite generar imágenes que de otra forma darían OOM.
- ¿Los modelos GGUF cuantizados reducen calidad?
- Apenas. Los formatos Q8_0 y fp8 son prácticamente indistinguibles del original. Q4_K_M reduce algo más la calidad pero cabe en GPUs de 4-6GB donde el modelo completo directamente no funciona.
- ¿El error OOM puede aparecer solo en el VAE aunque el modelo cargue bien?
- Sí. El VAE se ejecuta al final del proceso y puede fallar aunque el KSampler haya ido bien. Activa VAE tiling en el nodo VAEDecode o usa un VAE cuantizado para evitarlo.
- ¿Reiniciar ComfyUI libera VRAM?
- Sí. La VRAM fragmentada es un problema real en sesiones largas. Reiniciar el proceso limpia la memoria completamente y a menudo resuelve OOM que aparecen de repente en workflows que antes funcionaban.