
Reproduje un workflow viral de LTXV-2.3 + RTX Super Resolution en ComfyUI (con datos reales)
Hace poco descubrí un workflow de dos etapas que circula en YouTube: generación de vídeo con audio sincronizado mediante LTXV-2.3 en ComfyUI, seguida de escalado a 4K con el upscaler RTX de Nvidia. La promesa era atractiva. Lo que encontré fue más interesante aún: un pipeline real, reproducible, pero lleno de trampas que solo descubrirías ejecutándolo.
Descargué los JSON directamente de la descripción del vídeo, los ejecuté en una RTX 3090 24GB con ComfyUI v0.27.0, y documenté todo lo que pasó: tiempos reales, consumo de VRAM, problemas inesperados y cómo resolverlos. Esto no es un tutorial de documentación oficial. Es lo que sucedió cuando intenté replicar exactamente lo que veía en pantalla.
De un vistazo: Especificaciones del Pipeline
| Aspecto | Detalles |
|---|---|
| Etapa 1: Generación de vídeo | LTXV-2.3 distilled (22B) + audio sincronizado |
| Etapa 2: Escalado | RTX Video Super Resolution a 4K (3840x2160) |
| Tiempo total | ~10-11 minutos (463s + 176s) |
| VRAM pico | 22.9GB (RTX 3090 24GB mínimo) |
| Salida final | 1920x1024 → 3840x2160, 25fps, h264 + audio AAC |
| Descargas de modelos | ~32GB (nuevos) |
| Variante de cuantización | mxfp8_block32 (Ampere-compatible) |
El Pipeline Completo: Estructura de Dos Etapas
El workflow consta de dos grafos independientes que se encadenan:
- Etapa 1 (LTXV-2.3 T2V): Transforma un prompt de texto + audio descriptivo en un vídeo de 1920x1024 a 25fps con pista de audio embebida.
- Etapa 2 (RTX SR): Toma ese vídeo y lo escala a 3840x2160 (4K) manteniendo el frame rate.
Ambos workflows llegaron listos para ejecutar, pero la realidad de hacerlos funcionar fue bastante diferente a lo que sugería la apariencia de “solo cargar y ejecutar”.
Etapa 1: LTXV-2.3 con Audio Sincronizado
Arquitectura del Grafo
El primer workflow es una máquina compleja de 15+ nodos. La cadena principal funciona así:
- DiffusionModelLoaderKJ carga el transformer distilled de 22B (cuantizado a mxfp8_block32)
- DualCLIPLoaderGGUF carga Gemma-3-12B (cuantizado a IQ4_XS) como text encoder
- CLIPTextEncode procesa prompts positivos y negativos
- LTXVScheduler construye el cronograma de difusión (8 pasos, max_shift 2.05, base_shift 0.95)
- SamplerCustomAdvanced ejecuta la generación a resolución base (768x512, 251 frames)
- LTXVLatentUpsampler escala el latente x2 espacialmente
- SamplerCustomAdvanced (segunda pasada) refina con solo 3 pasos sobre el latente escalado
- LTXVSeparateAVLatent divide el latente conjunto vídeo+audio
- VAEDecodeTiled + LTXVAudioVAEDecode decodifican vídeo y audio por separado
- VHS_VideoCombine mezcla ambos en un mp4 con pista de audio embebida
🏗️ Workflow: LTXV-2.3 (1.1) T2V con audio
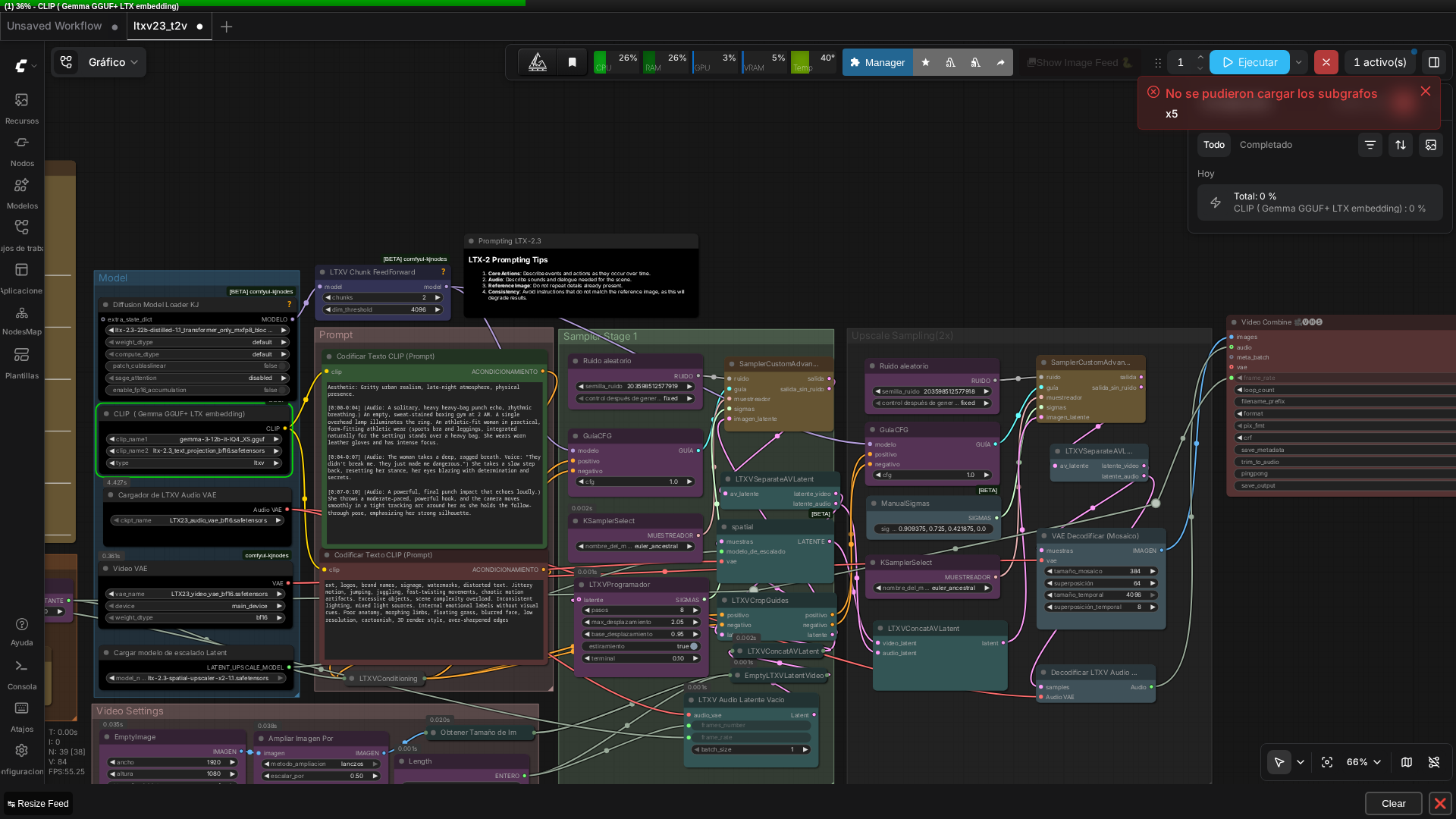 Captura real del grafo completo (15+ nodos) corriendo en ComfyUI v0.27.0.
Captura real del grafo completo (15+ nodos) corriendo en ComfyUI v0.27.0.
Descargas de Modelos Necesarios
El workflow de texto a vídeo con audio en ComfyUI requiere descargar ~32GB de archivos nuevos (además de una instalación base de ComfyUI-LTXVideo):
| Modelo | Tamaño | Ubicación | Fuente |
|---|---|---|---|
| gemma-3-12b-it-IQ4_XS.gguf | 6.55GB | models/text_encoders/ o models/clip/ | unsloth/gemma-3-12b-it-GGUF |
| ltx-2.3-22b-distilled-1.1_transformer_only_mxfp8_block32.safetensors | 24GB | models/diffusion_models/ | Kijai/LTX2.3_comfy |
| ltx-2.3-spatial-upscaler-x2-1.1.safetensors | 996MB | models/latent_upscale_models/ | Lightricks/LTX-2.3 |
| ltx-2.3_text_projection_bf16.safetensors | 1GB | models/text_encoders/ | Kijai/LTX2.3_comfy |
| LTX23_video_vae_bf16.safetensors | 1.45GB | models/vae/ | Kijai/LTX2.3_comfy |
| LTX23_audio_vae_bf16.safetensors | 365MB | models/vae/ | Kijai/LTX2.3_comfy |
💡 Consejo: Planifica ancho de banda y almacenamiento antes de empezar. El transformer distilled de 22B es el componente más pesado con diferencia. Si tu conexión es lenta, inicia las descargas y déjalas correr de noche.
Por Qué mxfp8_block32 en una RTX 3090
Este detalle técnico es crítico para el workflow LTX-2.3 en Ampere. Las GPUs RTX serie 30 (Ampere) no tienen instrucciones matmul FP8 nativas. El workflow especifica mxfp8_block32 porque ejecuta el modelo de 22B sobre tensor cores BF16 estándar, con calidad casi idéntica a fp8_scaled pero sin depender de operaciones que la tarjeta no puede hacer nativamente.
Si usas la variante fp8_scaled normal en una 3090, el workflow fallará o caerá en emulación lenta. No es una opción; es la diferencia entre que funcione o que no.
Números Reales de Ejecución
La ejecución completa del workflow LTXV-2.3 en mi RTX 3090 24GB tomó 463.39 segundos (7 minutos 43 segundos).
Desglose por etapa:
- Sampling a resolución base (8 pasos): ~77 segundos
- Primer paso: ~25 segundos (incluye overhead de carga del modelo)
- Pasos 2-8: ~9.7 segundos cada uno
- Refinamiento con latente escalado x2 (3 pasos): ~207 segundos
- ~69 segundos por paso (mucho más pesado debido al latente escalado)
- Codificación de texto CLIP/Gemma + decodificación VAE/audio: ~179 segundos
Consumo de VRAM pico: 22.914MB solo para el modelo LTXAV. Esto deja apenas 1GB de margen en una tarjeta de 24GB. No es cómodo. No es seguro. Es exactamente lo que cabe.
Resultado final: 1920x1024, 25fps, 251 frames (~10 segundos), h264 + audio AAC sincronizado. El audio ambiental (descripto en el prompt como gimnasio de boxeo) era genuinamente coherente, no solo ruido decorativo.
Vídeo real generado con este workflow exacto (prompt de gimnasio de boxeo incluido en el JSON original), sin editar.
⚠️ Importante: La generación LTXV-2.3 toma ~7.7 minutos en RTX 3090 con un pico de 22.9GB de VRAM. No hay margen de error: necesitas exactamente 24GB, no menos. Si tienes una 3080 Ti de 12GB o una 4070 Ti, este workflow no funcionará sin redimensionar significativamente la salida.
Problemas Reales Encontrados
Problema 1: El LTXVAudioVAELoader Busca en la Carpeta Equivocada
El nodo LTXVAudioVAELoader tiene hardcodeado folder_paths.get_filename_list('checkpoints'), lo que significa que solo escanea models/checkpoints/, no models/vae/ donde viven los VAE de audio.
Síntoma: El desplegable muestra “Value not in list” y la cola falla.
Solución: Copia o crea un symlink de LTX23_audio_vae_bf16.safetensors en models/checkpoints/. Es un hack, pero funciona inmediatamente.
Problema 2: Custom Nodes Desactualizados
Cargué el workflow y el frontend mostró “No se pudieron cargar los subgrafos” x5. Varios nodos marcados [BETA] mostraban opciones de desplegable incorrectas o genéricas.
Causa raíz: El paquete comfyui-kjnodes que tenía instalado llevaba ~4 meses desactualizado. El soporte para LTXV-2.3 llegó mucho después de su último commit.
Solución:
cd custom_nodes/comfyui-kjnodes
git pull
pip install -r requirements.txt
# Reinicia ComfyUIDespués de la actualización (240 commits de retraso), el workflow cargó limpio. La lección aquí es obvia: para modelos virales nuevos, siempre comprueba que tus custom nodes estén al día antes de asumir que el JSON está roto.
Problema 3: Git Bloqueado por Permisos de Archivo
El git pull falló inicialmente con “confirma tus cambios o guárdalos antes de fusionar”, pero git diff mostró solo cambios de permisos (100644 → 100755) sin ediciones reales.
Solución:
git config core.fileMode false
git pullEsto limpió el falso positivo sin riesgo.
📌 A tener en cuenta: Los problemas más comunes son custom nodes desactualizados y rutas de carpeta incorrectas. Antes de ejecutar el workflow LTXV-2.3, actualiza comfyui-kjnodes y copia el audio VAE a checkpoints/. Te ahorrarás una hora de debugging.
Etapa 2: RTX Video Super Resolution a 4K
Arquitectura Simple
El segundo workflow es mucho más directo:
- VHS_LoadVideo carga el mp4 del workflow 1
- RTXVideoSuperResolution escala a 3840x2160 (modo ULTRA)
- VHS_VideoCombine mezcla el resultado en mp4
El nodo viene de Nvidia_RTX_Nodes_ComfyUI (instalable vía ComfyUI-Manager buscando “RTX”) y depende del paquete pip nvidia-vfx.
🏗️ Workflow: RTX Video Super Resolution (4K)
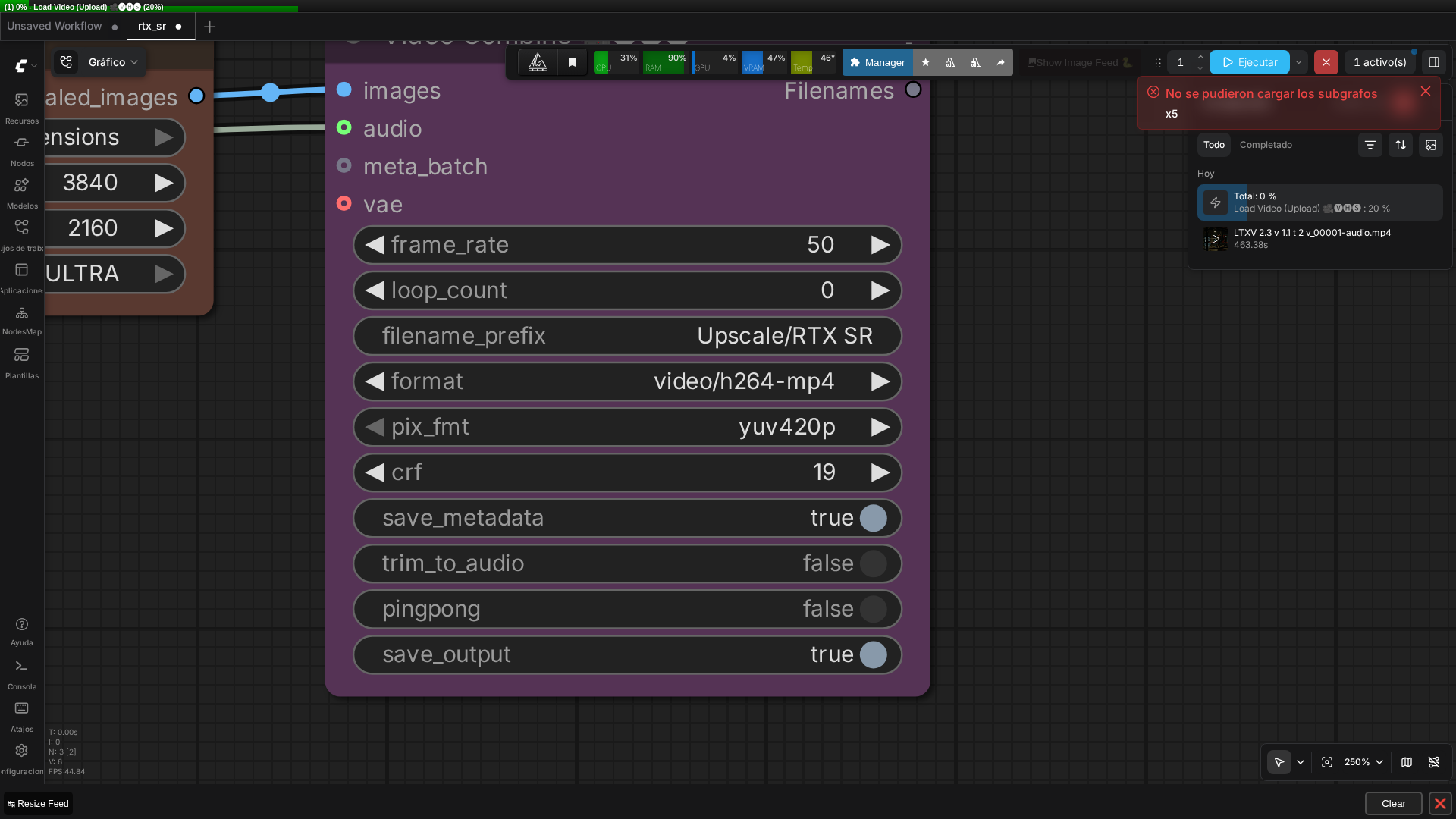 Captura real del grafo de 3 nodos (VHS_LoadVideo → RTXVideoSuperResolution → VHS_VideoCombine).
Captura real del grafo de 3 nodos (VHS_LoadVideo → RTXVideoSuperResolution → VHS_VideoCombine).
Números de Ejecución
Tiempo total: 175.88 segundos (2 minutos 56 segundos).
Resultado: Un mp4 genuinamente 3840x2160 con bordes visiblemente más nítidos, gradientes de iluminación más limpios, sin artefactos de escalado ni ghosting en la figura en movimiento.
Salida real en 4K (nota: se reproduce a doble velocidad por el bug de frame_rate explicado abajo — dura ~5s en vez de ~10s).
La Trampa del Frame Rate
Aquí está el problema que casi todos los usuarios pisarán: el JSON descargado tiene frame_rate fijado en 50 en el nodo VHS_VideoCombine, pero el vídeo fuente (del workflow 1) está a 25fps.
RTXVideoSuperResolution solo escala espacialmente, no interpola frames. Así que el vídeo de salida tiene el mismo número de frames pero se reproduce a 50fps en vez de 25fps. El vídeo 4K final se reproduce al doble de velocidad y dura la mitad (4.98 segundos en vez de ~10 segundos).
Solución: Antes de encolar, reajusta manualmente el widget frame_rate de VHS_VideoCombine para que coincida con el fps real de tu vídeo fuente.
Requisitos de Hardware y Viabilidad
Este pipeline no es escalable hacia abajo:
| Componente | Requisito Mínimo |
|---|---|
| VRAM | 24GB (no 20GB, no 16GB) |
| Espacio en disco | ~50GB (modelos + vídeos intermedios) |
| Tiempo total | ~10-11 minutos (LTXV + SR) |
| Ancho de banda de descarga | 32GB+ de modelos nuevos |
Una RTX 3090 24GB es el mínimo viable. Una 4090 o tarjeta profesional (L40S, H100) daría más margen y potencialmente pasos más rápidos, pero no cambiaría el orden de magnitud.
Preguntas Frecuentes
¿Se puede correr el modelo distilled de LTXV-2.3 en una RTX 3090?
Sí, pero solo con la variante del transformer mxfp8_block32, no fp8_scaled. Las GPU serie 30 de Nvidia no tienen soporte nativo de matmul FP8, y mxfp8_block32 corre el mismo modelo distilled de 22B sobre tensor cores BF16 estándar. El pico de VRAM reservada fue de 22.9GB, así que hace falta una tarjeta de 24GB completa.
¿Por qué mi workflow de LTXV-2.3 descargado muestra un error ‘no se pudieron cargar los subgrafos’ en ComfyUI?
Normalmente significa que el paquete de custom nodes comfyui-kjnodes está desactualizado y le faltan las clases de nodo que referencia el workflow (el soporte de LTX-2.3 es muy reciente). Actualízalo con git pull en custom_nodes/comfyui-kjnodes, reinstala su requirements.txt, y reinicia ComfyUI.
¿Por qué mi vídeo en 4K de RTX Video Super Resolution se reproduce al doble de velocidad?
RTXVideoSuperResolution solo hace escalado espacial (de resolución), no interpolación de frames. El resultado tiene el mismo número de frames que la entrada. Si el widget frame_rate del nodo VHS_VideoCombine no coincide con el fps real de tu vídeo fuente, el resultado se reproduce demasiado rápido. Reajústalo antes de encolar.
¿Dónde busca ComfyUI el fichero del LTXVAudioVAELoader?
A diferencia de la mayoría de cargadores de VAE, este nodo nativo de ComfyUI escanea específicamente la carpeta models/checkpoints/, no models/vae/. Si tu fichero de VAE de audio vive en vae/, crea un symlink o cópialo a checkpoints/ o el desplegable del nodo mostrará ‘Value not in list’.
¿Puedo saltarme la etapa de refinamiento (3 pasos) para acelerar?
Técnicamente sí, pero el resultado será notablemente más suave y menos detallado. Los 3 pasos de refinamiento sobre el latente escalado x2 son lo que convierte la salida de 768x512 en algo visualmente sólido a 1920x1024. No recomendado.
¿El escalado RTX SR funciona con GPUs AMD?
No. El nodo RTXVideoSuperResolution es específico de Nvidia y depende de nvidia-vfx. AMD no tiene un equivalente nativo en ComfyUI.
Sigue leyendo
Si los formatos de cuantización como mxfp8_block32 y GGUF no te resultan familiares, nuestra guía de GGUF en ComfyUI explica qué hacen realmente a la calidad del modelo y a la VRAM. Para comparar LTXV-2.3 con otro modelo local de generación de vídeo, consulta nuestra guía completa de Wan 2.2. Y si quieres profundizar en el escalado de vídeo más allá de RTX SR, tenemos una guía de video upscale en ComfyUI.
Conclusión
🏆 Nuestra recomendación
Ambos workflows funcionan exactamente como se anuncia en una RTX 3090 de 24GB. LTXV-2.3 distilled produce vídeo con audio genuinamente bueno en menos de 8 minutos. El escalado RTX SR es rápido y limpio a 4K real.
Si tienes una RTX 3090 24GB y estás dispuesto a depurar problemas de custom nodes, este pipeline es viable y produce resultados reales de calidad profesional. Si trabajas con tarjetas más pequeñas (3080 Ti, 4070 Ti) o prefieres una experiencia sin configuración, ahorra tiempo y espera a que Nvidia o Lightricks lancen versiones optimizadas.
Si decides intentarlo, descarga los JSON de la descripción del vídeo original, verifica que tu comfyui-kjnodes esté actualizado, copia el audio VAE a models/checkpoints/, y reajusta el frame rate antes de encolar. Documentar lo que encuentres en el camino será valioso para quienes vengan después.
Siguientes pasos en ComfyUI
Primeros pasos
Preguntas frecuentes
- ¿Se puede correr el modelo distilled de LTXV-2.3 en una RTX 3090?
- Sí, pero solo con la variante del transformer mxfp8_block32, no fp8_scaled -- las GPU serie 30 de Nvidia no tienen soporte nativo de matmul FP8, y mxfp8_block32 corre el mismo modelo distilled de 22B sobre tensor cores BF16 estándar. El pico de VRAM reservada fue de 22.9GB, así que hace falta una tarjeta de 24GB completa.
- ¿Por qué mi workflow de LTXV-2.3 descargado muestra un error 'no se pudieron cargar los subgrafos' en ComfyUI?
- Normalmente significa que el paquete de custom nodes comfyui-kjnodes está desactualizado y le faltan las clases de nodo que referencia el workflow (el soporte de LTX-2.3 es muy reciente). Actualízalo con git pull en custom_nodes/comfyui-kjnodes, reinstala su requirements.txt, y reinicia ComfyUI.
- ¿Por qué mi vídeo en 4K de RTX Video Super Resolution se reproduce al doble de velocidad?
- RTXVideoSuperResolution solo hace escalado espacial (de resolución), no interpolación de frames -- el resultado tiene el mismo número de frames que la entrada. Si el widget frame_rate del nodo VHS_VideoCombine no coincide con el fps real de tu vídeo fuente, el resultado se reproduce demasiado rápido. Reajústalo antes de encolar.
- ¿Dónde busca ComfyUI el fichero del LTXVAudioVAELoader?
- A diferencia de la mayoría de cargadores de VAE, este nodo nativo de ComfyUI escanea específicamente la carpeta models/checkpoints/, no models/vae/. Si tu fichero de VAE de audio vive en vae/, crea un symlink o cópialo a checkpoints/ o el desplegable del nodo mostrará 'Value not in list'.


