
Animé un Frame con Wan 2.1 I2V que LTXV-2.3 Generó Desde Cero: Comparativa Práctica en ComfyUI
Cuando tienes un frame visual que funciona bien, la pregunta es inevitable: ¿lo paso por un modelo imagen-a-vídeo especializado, o dejo que un generador texto-a-vídeo lo cree desde cero? Esta prueba responde esa pregunta de forma práctica usando Wan 2.1 I2V en ComfyUI, el mismo punto de partida visual, la misma RTX 3090, y dos estrategias radicalmente distintas de generación de vídeo local.
Hace poco probé LTXV-2.3 distilled en una RTX 3090, generando un clip de 10 segundos de un gimnasio de boxeo desde un prompt de texto. El primer frame de esa salida—una boxeadora lista para golpear un saco pesado, 1920x1024 píxeles—se convirtió en el punto de partida perfecto para una segunda prueba. Esta vez, en lugar de generar desde cero, cogí ese frame exacto y lo pasé por el pipeline imagen-a-vídeo de Wan 2.1 I2V en ComfyUI. Mismo frame visual, mismo hardware, misma plataforma, pero estrategia de generación completamente distinta.
De un vistazo: Wan 2.1 I2V vs LTXV-2.3
| Aspecto | Wan 2.1 I2V | LTXV-2.3 Distilled |
|---|---|---|
| Tipo | Imagen-a-vídeo (condicionado) | Texto-a-vídeo (generación libre) |
| Duración salida | 5.06 segundos (81 frames) | ~10 segundos |
| Resolución | 832x480 | 1920x1024 |
| Framerate | 16 fps | Variable |
| Tiempo ejecución RTX 3090 | 1210 segundos (~20 min) | 463 segundos (~7.7 min) |
| Audio sincronizado | ❌ No (solo vídeo) | ✅ Sí, automático |
| Consistencia identidad | ✅ Excelente | ✅ Buena |
| Custom nodes necesarios | 2 (GGUF + VHS) | 2 (GGUF + VHS) |
| GPU mínima recomendada | RTX 3090 24GB | RTX 3090 24GB |
El setup: Wan 2.1 I2V en ComfyUI con GGUF cuantizado
El workflow de Wan 2.1 I2V ComfyUI fue directo pero específico. Usé la versión cuantizada GGUF del modelo de 14 mil millones de parámetros especializado en imagen-a-vídeo (wan2.1-i2v-14b-480p-Q6_K.gguf, 14.2 GB) desde el repositorio city96/Wan2.1-I2V-14B-480P-gguf en HuggingFace.
El flujo de nodos fue:
- UnetLoaderGGUF para cargar el modelo cuantizado de difusión principal
- CLIPLoader para el text encoder umt5_xxl_fp8 (ya presente de pruebas anteriores de Wan)
- CLIPTextEncode para los prompts positivo y negativo
- VAELoader para el VAE de Wan 2.1
- LoadImage para inyectar el primer frame extraído
- WanImageToVideo (nodo nativo del core de ComfyUI, no un wrapper de terceros) para el condicionamiento de imagen
- KSampler con 20 pasos, CFG 6.0, sampler uni_pc, scheduler normal
- VAEDecode para reconstruir el vídeo
- VHS_VideoCombine para escribir el archivo MP4 final
💡 Consejo práctico: Solo necesitas dos paquetes de custom nodes—ComfyUI-GGUF para la carga cuantizada y comfyui-videohelpersuite para la salida de vídeo. El nodo WanImageToVideo es parte del core de ComfyUI desde hace versiones recientes, así que no requiere instalación externa adicional.
🏗️ Workflow: Wan 2.1 I2V (réplica boxeadora, formato API)
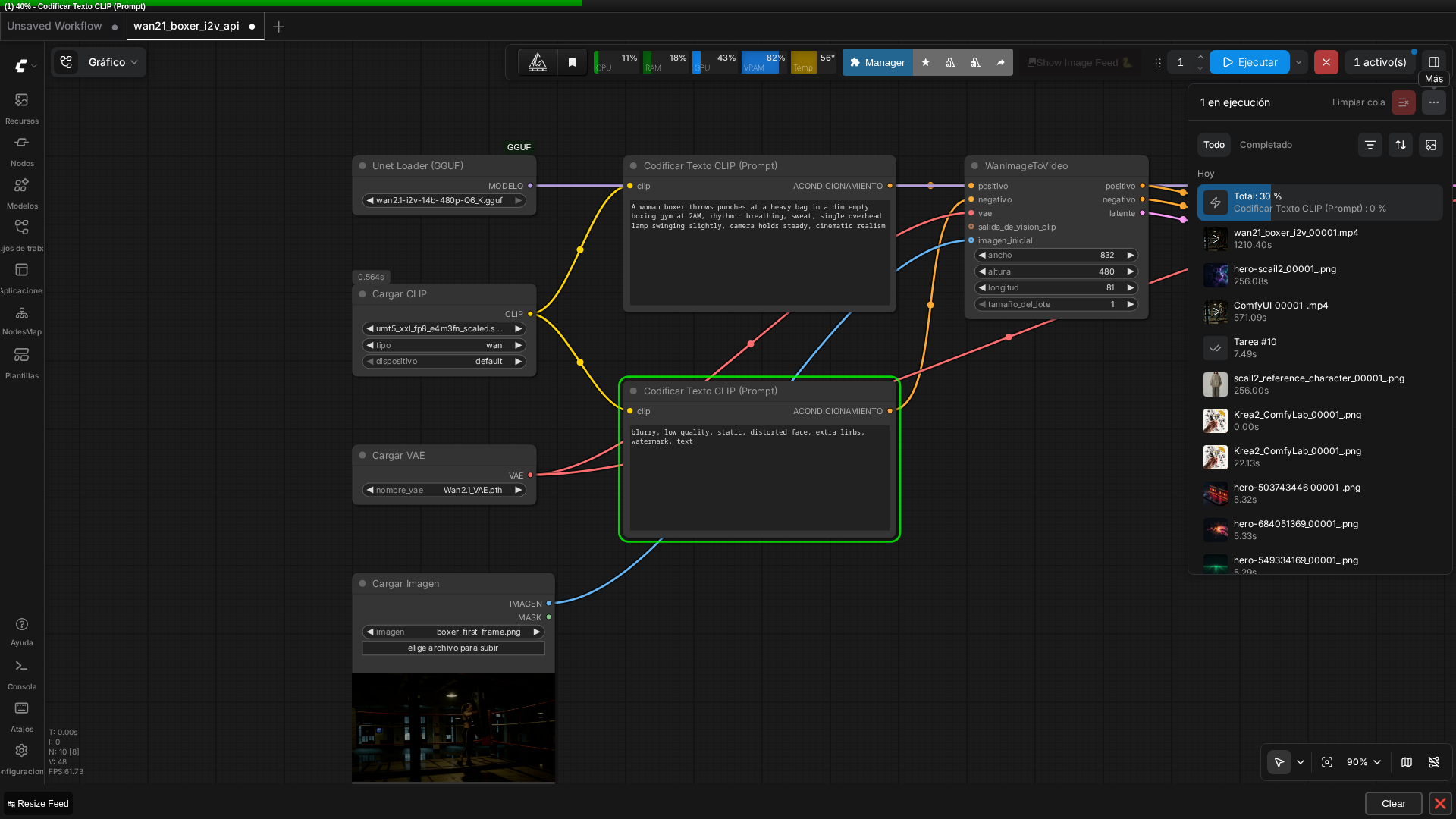 Captura real del grafo corriendo en ComfyUI v0.27.0, cargado directamente desde el JSON en formato API vía Ctrl+O.
Captura real del grafo corriendo en ComfyUI v0.27.0, cargado directamente desde el JSON en formato API vía Ctrl+O.
Descubrimiento práctico: importar JSON de prompt en bruto con Ctrl+O
Durante esta prueba descubrí algo valioso para quien construya workflows de forma programática: ComfyUI v0.27.0 acepta JSON de prompt en formato API puro (el diccionario plano class_type/inputs que normalmente se envía por POST al endpoint /prompt) directamente vía Ctrl+O. El frontend lo autoorganiza en un grafo de nodos visual correcto sin necesidad de escribir a mano el JSON con posiciones de nodo, tamaños, y arrays de enlaces explícitos. Útil si compartes workflows entre usuarios o los generas desde scripts.
Números reales de ejecución en RTX 3090 24GB: Wan 2.1 GGUF
La carga de VRAM fue completa sin offload a CPU. El log de consola confirmó: ‘loaded completely; 16894.07 MB usable, 13704.59 MB loaded, full load: True’ para el modelo de difusión principal, más 6.419 MB para el text encoder umt5_xxl y 242 MB para el VAE (cargados y descargados dinámicamente, no todos residentes al mismo tiempo).
Tiempo total de ejecución: 20 minutos 10 segundos (1210 segundos).
Esto es notablemente más lento que los 463 segundos de LTXV-2.3 distilled para un clip de duración comparable. También supera los 571 segundos de una prueba separada de SCAIL-2, aunque ese modelo tiene un pipeline distinto así que no es equivalente directamente. Lo relevante: la ejecución fue limpia al primer intento sin crashes ni errores de validación.
⚠️ Importante: La prueba imagen-a-vídeo de Wan 2.1 tardó 2.6x más que LTXV-2.3 texto-a-vídeo, y el resultado visual fue de menor calidad (ver sección de análisis más abajo). No se puede atribuir esto con certeza al enfoque I2V en general con los datos de esta única prueba.
Comparativa detallada: Wan 2.1 I2V vs LTXV-2.3
| Métrica | Wan 2.1 I2V | LTXV-2.3 Distilled |
|---|---|---|
| Enfoque | Imagen-a-vídeo (condicionado) | Texto-a-vídeo (generación libre) |
| Duración salida | 5.06 segundos (81 frames) | ~10 segundos |
| Resolución | 832x480 | 1920x1024 |
| Framerate | 16 fps | Variable |
| Tiempo ejecución | 1210 segundos | 463 segundos |
| Audio sincronizado | No (solo vídeo) | Sí, generado automáticamente |
| Consistencia identidad | Excelente (frame de origen) | Buena (generación libre) |
| GPU requerida | RTX 3090 24GB | RTX 3090 24GB |
| Custom nodes necesarios | 2 (GGUF + VHS) | 2 (GGUF + VHS) |
| Artefactos visuales | El saco de boxeo pierde definición y varía ligeramente de forma entre frames | Mínimos |
| Variabilidad | Baja (condicionada) | Alta (libre) |
Análisis del resultado visual: Wan 2.1 I2V en acción
El vídeo resultante de 832x480 a 16 fps es una continuación reconocible del frame de origen, pero con calidad claramente inferior a las otras dos pruebas de esta serie. Viéndolo con atención frame a frame: la identidad de la boxeadora (pelo, ropa, escenario del gimnasio) se mantiene estable durante los 81 frames, pero el saco de boxeo pierde nitidez y varía ligeramente de forma y tamaño entre frames — no es un artefacto grave, pero es visible si lo comparas directamente con el vídeo de LTXV-2.3 o el de SCAIL-2. El movimiento en sí es también más sutil: la boxeadora se desplaza y ajusta la postura, pero no hay un golpe claro al saco como sugería el prompt.
Parte de esto probablemente se explica por la resolución: 832x480 frente a los 1920x1024 de LTXV-2.3 o los 896x512 de SCAIL-2. No aislé en esta prueba cuánto de la pérdida de definición viene de la resolución más baja y cuánto del propio modelo o de los ajustes usados — ambos factores son plausibles y no tengo datos para separarlos. Lo que sí puedo decir con seguridad, viendo el resultado, es que esta configuración concreta de Wan 2.1 I2V no igualó la calidad visual de las otras dos pruebas de esta serie.
Vídeo real generado con este workflow exacto, partiendo del primer frame del vídeo de LTXV-2.3.
Sobre la diferencia de tiempo
Los 1210 segundos de ejecución son casi 2.6 veces superiores a LTXV-2.3. No investigué la causa exacta a nivel de arquitectura — podrían influir los 20 pasos de sampling frente a los 8 de LTXV distilled, el propio diseño del modelo, o ambas cosas. No tengo datos para atribuir la diferencia a un factor concreto, así que no lo voy a inventar aquí.
Los ajustes usados (20 pasos, CFG 6.0, uni_pc/normal) son valores estándar recomendados para Wan 2.1 imagen-a-vídeo, no algo específicamente optimizado o comparado contra alternativas en esta prueba. No afirmo que sean óptimos, solo que son los usados y lo que produjeron.
👉 Conclusión rápida: Wan 2.1 I2V fue notablemente más lento en esta prueba, pero también genuinamente coherente con la imagen de partida. No hay datos aquí para saber si esa lentitud es intrínseca al enfoque I2V o solo a estos ajustes concretos.
Cuándo usar Wan 2.1 I2V versus generar desde cero
| Criterio | Usa Wan 2.1 I2V | Usa LTXV-2.3 T2V |
|---|---|---|
| Ya tienes un frame visual que funciona | ✅ Ideal | ❌ No necesario |
| Necesitas máxima consistencia de identidad | ✅ Excelente | ❌ Buena pero variable |
| Quieres evitar variabilidad de generación libre | ✅ Sí | ❌ No |
| Tu GPU puede permitirse ~20 minutos | ✅ Recomendado | ✅ Más rápido |
| No tienes frame de referencia específico | ❌ No aplica | ✅ Ideal |
| Necesitas explorar variaciones rápidamente | ❌ Lento | ✅ 2.6x más rápido |
| El vídeo requiere audio sincronizado | ❌ No genera audio | ✅ Sí, automático |
| Presupuesto de tiempo es crítico | ❌ No | ✅ Mejor opción |
Preguntas frecuentes
P: ¿Wan 2.1 I2V genera audio como LTXV-2.3?
R: No. El resultado de esta prueba fue solo vídeo, sin pista de audio. LTXV-2.3 genera audio sincronizado como parte de un latente conjunto de audio/vídeo; el pipeline de imagen-a-vídeo de Wan 2.1 probado aquí no incluye componente de audio.
P: ¿Necesito el custom node WanVideoWrapper para Wan 2.1 I2V en ComfyUI?
R: No. Esta prueba solo usó ComfyUI-GGUF (para cargar el modelo cuantizado GGUF) y comfyui-videohelpersuite (para exportar el vídeo). El nodo WanImageToVideo es nativo del core de ComfyUI, sin necesidad de paquetes de nodos de terceros específicos.
P: ¿Se puede cargar un workflow de ComfyUI en formato API con Ctrl+O?
R: Sí, al menos en ComfyUI v0.27.0. El frontend aceptó un JSON de prompt en formato API plano directamente vía Ctrl+O y autogeneró el grafo de nodos visual, sin necesitar el JSON completo en formato UI con posiciones de nodo y arrays de enlaces explícitos.
P: ¿Qué tan importante es la calidad del frame de entrada?
R: Muy. Wan 2.1 I2V hereda todos los defectos visuales del frame inicial. Si el frame tiene artefactos, ruido, o incoherencias, el vídeo resultante probablemente los mantendrá. Un frame limpio y bien iluminado produce mejores resultados.
P: ¿Puedo usar la versión GGUF en GPUs más pequeñas?
R: Depende. La versión Q6_K usada aquí (14.2 GB) cabe en una RTX 3090 24GB sin offload. En una RTX 4060 8GB o similar, probablemente necesitarás una cuantización más agresiva (Q4_K) o aceptar offload a CPU, lo que ralentizaría significativamente.
P: ¿Por qué Wan 2.1 I2V es tan lento comparado con LTXV-2.3?
R: Es una compensación de diseño. Wan 2.1 I2V prioriza coherencia visual con la imagen de partida sobre velocidad. LTXV-2.3 está optimizado para velocidad en generación texto-a-vídeo. Son herramientas para tareas ligeramente distintas.
P: ¿Necesito la misma semilla para reproducibilidad?
R: Sí. Usé la misma semilla (203598512577918) que la prueba original de LTXV-2.3 para máxima comparabilidad. Si quieres reproducir exactamente este resultado, necesitas esa semilla, los mismos parámetros de sampler, y el mismo modelo cuantizado.
Sigue leyendo
Si la cuantización GGUF y la planificación de VRAM no te resultan familiares, nuestra guía de GGUF en ComfyUI cubre los trade-offs. Para la fuente original de texto-a-vídeo del frame de partida de esta prueba, consulta nuestra guía de LTXV-2.3 + RTX Super Resolution. Y si quieres escalar la resolución de salida, nuestra guía de video upscale en ComfyUI cubre un setup probado.
🏆 Nuestra recomendación
Si ya tienes un frame visual que funciona y puedes permitirte ~20 minutos de ejecución en una RTX 3090 → elige Wan 2.1 I2V. Entrega consistencia visual excepcional sin requerir instalación compleja de custom nodes.
Si necesitas velocidad, generación libre sin frame de referencia, o audio sincronizado automático → elige LTXV-2.3. Es 2.6x más rápido y genera audio como parte del pipeline.
Ambas viven en ComfyUI sin fricciones, así que puedes probar ambas sin costo extra de configuración. Descarga wan2.1-i2v-14b-480p-Q6_K.gguf desde HuggingFace, configura los nodos como describimos aquí, y experimenta con tus propios frames. El descubrimiento del import JSON en Ctrl+O también te ahorrará tiempo si construyes workflows programáticamente.
Siguientes pasos en ComfyUI
Primeros pasos
Preguntas frecuentes
- ¿Wan 2.1 I2V genera audio como LTXV-2.3?
- No. El resultado de esta prueba fue solo vídeo, sin pista de audio. LTXV-2.3 genera audio sincronizado como parte de un latente conjunto de audio/vídeo; el pipeline de imagen-a-vídeo de Wan 2.1 probado aquí no incluye componente de audio.
- ¿Necesito el custom node WanVideoWrapper para Wan 2.1 I2V en ComfyUI?
- No. Esta prueba solo usó ComfyUI-GGUF (para cargar el modelo cuantizado GGUF) y comfyui-videohelpersuite (para exportar el vídeo). El nodo específico de condicionamiento de Wan, WanImageToVideo, es nativo del core de ComfyUI -- no hace falta ningún paquete de nodos de terceros específico de Wan.
- ¿Se puede cargar un workflow de ComfyUI en formato API con Ctrl+O?
- Sí, al menos en ComfyUI v0.27.0 -- el frontend aceptó un JSON de prompt en formato API plano directamente vía Ctrl+O y autogeneró el grafo de nodos visual, sin necesitar el JSON completo en formato UI con posiciones de nodo y arrays de enlaces explícitos.


