
Wan 2.2 I2V vs Wan 2.1: Mismo Primer Frame, Misma RTX 3090, Calidad Claramente Distinta
Hace poco probé Wan 2.1 I2V para animar el primer frame de un video de boxeo generado con LTXV-2.3. Los resultados fueron funcionales, pero algo predecibles: movimientos suaves pero imprecisos, pérdida de nitidez en los detalles. Ahora he repetido exactamente la misma prueba con Wan 2.2 I2V usando la misma RTX 3090, el mismo frame inicial, incluso la misma semilla aleatoria. Lo que encontré no fue solo una mejora incremental, sino un cambio cualitativo real en cómo el modelo procesa la información visual frame a frame.
Wan 2.2 abandona el modelo único de Wan 2.1 por un diseño de mixture-of-experts (MoE) con dos modelos separados especializados: uno para los primeros pasos de denoising con alto ruido, otro para los pasos finales de refinamiento con bajo ruido. No es un cambio cosmético de versión. Es una restructuración fundamental de cómo el modelo genera video — aunque, como se detalla más abajo, esta prueba no aísla si esa restructuración es la causa exacta de la mejora observada.
De un vistazo: Wan 2.2 I2V vs Wan 2.1 I2V
| Aspecto | Wan 2.1 I2V | Wan 2.2 I2V |
|---|---|---|
| Arquitectura | Modelo único 14B | MoE: HighNoise (14B) + LowNoise (14B) |
| Tiempo ejecución | 20 min 10 seg | 18 min 3 seg ⚡ |
| Definición visual | Suave, menos nítida | Nítida, consistente |
| Movimiento | Ambiguo, suave | Decidido, intencional |
| Cuantización usada | Q6_K | Q4_K_M |
| VRAM pico real | ~16GB (modelo cargado completo) | ~16GB (carga dinámica, un modelo de 14B a la vez) |
| Especialización | Única | Dos modelos especializados |
La arquitectura MoE de Wan 2.2: dos modelos, un flujo
Wan 2.1 usaba un único modelo unificado de 14B parámetros que manejaba todo el proceso de denoising de principio a fin. Wan 2.2 divide esa responsabilidad en dos especialistas:
Wan2.2-I2V-A14B-HighNoise: Se encarga de los primeros pasos del denoising, cuando el ruido es alto y la tarea es más sobre establecer estructura y movimiento general. Este modelo toma decisiones amplias sobre qué va a pasar en el video.
Wan2.2-I2V-A14B-LowNoise: Toma el relevo en los últimos pasos, cuando el ruido residual es bajo y el trabajo es de refinamiento y detalle. Aquí es donde se resuelve la nitidez, se definen bordes, se añade definición muscular.
💡 Consejo práctico: En ComfyUI, esto se traduce en dos nodos
UnetLoaderGGUF(uno por modelo), dos nodosModelSamplingSD3, y crucialmente, dos nodosKSamplerAdvanceden secuencia: el primero usa HighNoise para los pasos 0-10, el segundo usa LowNoise para los pasos 10-20, pasando el latente con ruido residual de uno al otro.
Configuración de la prueba: controlado al milímetro
Para que esta comparación fuera válida, mantuve todo idéntico a la prueba anterior de Wan 2.1:
- Imagen de partida: Primer frame extraído del video de boxeo de LTXV-2.3
- Semilla: 203598512577918 (la misma)
- Hardware: RTX 3090 24GB
- Entorno: ComfyUI v0.27.0
- Resolución y duración: 832x480, 81 frames, 16fps
- Parámetros de sampling: 20 pasos totales, cfg 3.5, sampler euler, scheduler simple
Los únicos cambios fueron los modelos (Wan 2.2 en lugar de Wan 2.1) y la cuantización específica elegida para hacerlo viable en 24GB.
📌 A tener en cuenta: Mantener variables controladas es esencial para aislar el impacto real de la arquitectura MoE, aunque la cuantización diferente introduce una variable que no se puede separar completamente.
GGUF, cuantización y la realidad de 24GB
Wan 2.2 I2V requiere dos modelos de 14B residentes, aunque no completamente simultáneos gracias a la carga dinámica. Descargué Wan2.2-I2V-A14B-HighNoise-Q4_K_M.gguf y Wan2.2-I2V-A14B-LowNoise-Q4_K_M.gguf de QuantStack en HuggingFace (9.65GB cada uno, ~19.3GB combinados).
La cuantización Q4_K_M fue una elección deliberada: mantiene la calidad de forma razonable mientras comprime lo suficiente para que dos modelos de 14B quepan en una tarjeta de 24GB. La prueba anterior de Wan 2.1 usó Q6_K (mejor calidad, pero un único modelo). Aquí viene un detalle que conviene aclarar: ¿la mejora de calidad viene de la arquitectura MoE, de la cuantización distinta, o del entrenamiento mejorado de Wan 2.2 en sí? Sin datos de ablación para separarlo, lo reconozco desde el principio.
El text encoder umt5_xxl y el VAE de Wan 2.1 (sí, Wan 2.2 reutiliza el VAE de Wan 2.1) ya estaban en caché de pruebas anteriores, así que no añadieron tiempo de descarga.
Números reales de ejecución: velocidad y VRAM
| Métrica | Wan 2.1 I2V | Wan 2.2 I2V | Diferencia |
|---|---|---|---|
| Tiempo total | 20 min 10 seg | 18 min 3 seg | -2 min 7 seg (-10.5%) ⚡ |
| Modelos en uso | 1 × 14B | 2 × 14B (carga dinámica) | — |
| VRAM HighNoise pico | — | 9.337 GB | — |
| VRAM LowNoise pico | — | 9.337 GB | — |
| VRAM Text encoder | 6.419 GB | 6.419 GB | (igual) |
| VRAM VAE | 242 MB | 242 MB | (igual) |
| Salida generada | 832x480, 81 frames | 832x480, 81 frames | (idéntico) |
Lo más notable: Wan 2.2 fue más rápido pese a correr dos modelos de 14B. Esto refleja eficiencias en el diseño MoE y posiblemente en la cuantización Q4_K_M vs Q6_K. No hubo crashes, errores de validación, ni problemas de VRAM. Corrida limpia al primer intento.
La diferencia visual: donde ocurre la mejora real
Aquí es donde la prueba se vuelve concreta. Inspeccioné frame a frame varios puntos del clip de 81 frames, no solo uno.
Definición del saco de boxeo: En Wan 2.1, el saco se suavizaba progresivamente conforme avanzaban los frames, perdiendo nitidez y bordes bien definidos. En Wan 2.2 I2V, la geometría del saco se mantiene nítida y consistente durante los 81 frames completos.
Decisión del movimiento: Wan 2.1 generó un movimiento más ambiguo, algo así como un desplazamiento de peso lateral sin acción clara. Wan 2.2 produce un golpe real: el brazo se extiende, el guante rojo hace contacto claro y decisivo con el saco, hay transferencia de energía visible. No es movimiento por movimiento, es acción intencional.
Definición muscular y nitidez general: Los músculos del brazo que golpea tienen más definición en Wan 2.2. Los detalles de la piel, la ropa, el fondo del gimnasio, todos son visiblemente más nítidos. No es un efecto de contraste falso; es más información visual resuelta.
⚠️ Importante: Es una mejora observable y específica, no una impresión subjetiva. Cuando digo “mejor”, me refiero a estas tres cosas concretas: nitidez mantenida, movimiento intencional, y detalle muscular.
Vídeo real generado con este workflow exacto, partiendo del mismo primer frame que las pruebas de LTXV-2.3 y Wan 2.1.
Workflow en ComfyUI: cómo se estructura Wan 2.2 I2V
El template oficial video_wan2_2_14B_i2v.json (que es también un subgrafo nativo de ComfyUI) estructura el flujo así:
- Carga de modelos: Dos nodos
UnetLoaderGGUF(uno por cada GGUF de HighNoise y LowNoise) - Configuración de sampling: Dos nodos
ModelSamplingSD3con shift=5.0 - Text encoding:
CLIPLoader(type=‘wan’) + dos nodosCLIPTextEncode - Preparación de imagen:
LoadImage(el primer frame) +VAELoader - Conversión a latente:
WanImageToVideo(832x480, 81 frames, batch_size 1) - Denoising HighNoise:
KSamplerAdvanced#1 con modelo HighNoise, pasos 0-10,add_noise=enable,return_with_leftover_noise=enable - Denoising LowNoise:
KSamplerAdvanced#2 con modelo LowNoise, pasos 10-20,add_noise=disable, tomando el latente del sampler anterior - Decodificación:
VAEDecode+VHS_VideoCombine
Los parámetros vienen de los valores por defecto del template (20 pasos, cfg 3.5, euler, simple scheduler). No los ajusté ni optimicé para esta prueba; es una ejecución “tal como viene”.
El template también ofrece una ruta opcional con LoRA de distillation de 4 pasos (lightx2v) para generación mucho más rápida, pero no la usé aquí. Eso merece una prueba separada.
🏗️ Workflow: Wan 2.2 I2V (réplica boxeadora, MoE doble modelo)
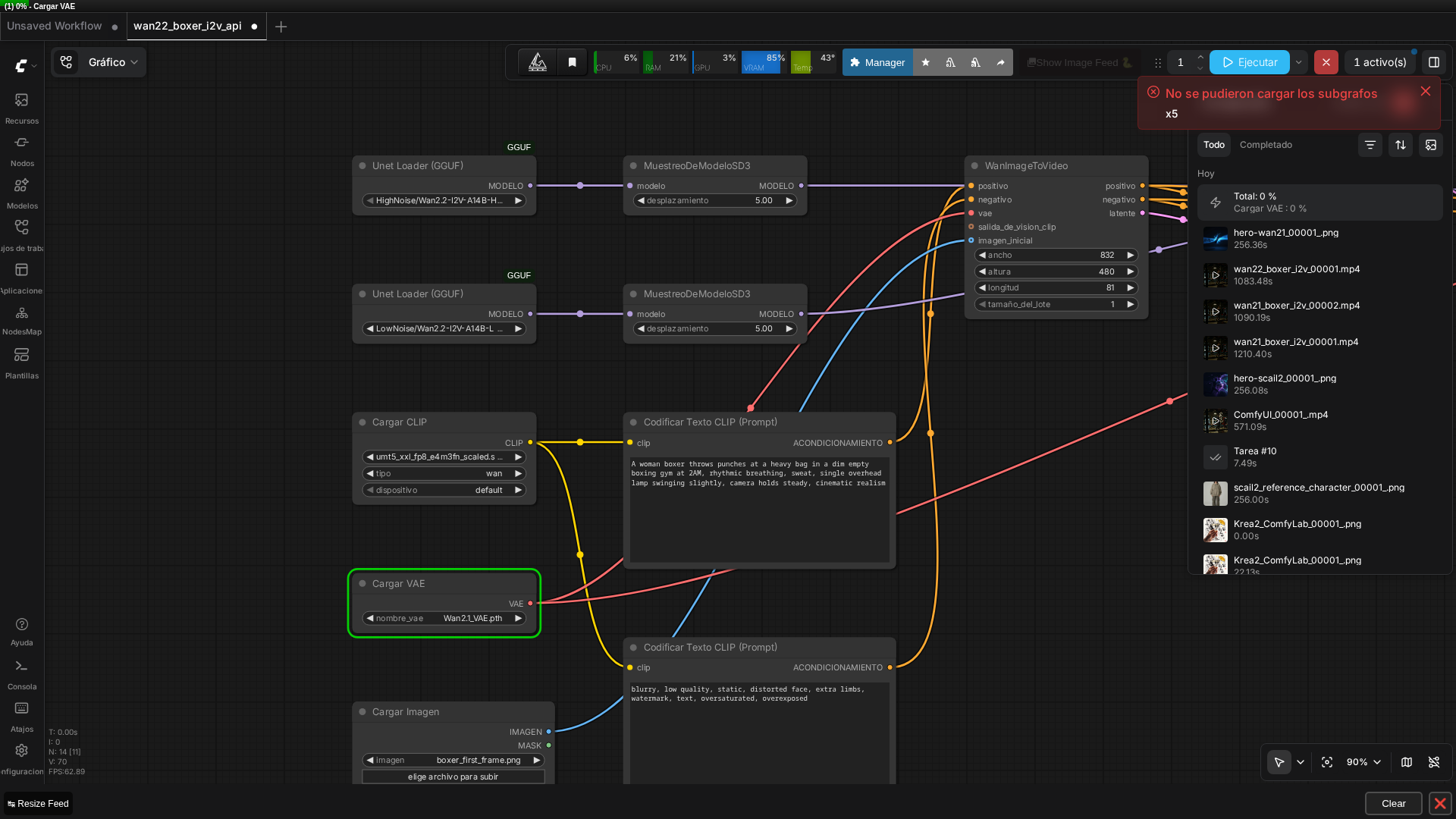 Captura real del grafo de doble modelo en ComfyUI v0.27.0, con ambos nodos UnetLoaderGGUF y el prompt real visible.
Captura real del grafo de doble modelo en ComfyUI v0.27.0, con ambos nodos UnetLoaderGGUF y el prompt real visible.
¿Qué causa realmente la mejora? Limitaciones de esta prueba
Aquí debo ser honesto: esta prueba no aisló qué factor es responsable de la diferencia de calidad. Tres cosas podrían estar contribuyendo:
- La arquitectura MoE en sí: Dos modelos especializados podrían genuinamente procesar mejor la información que un modelo único.
- La cuantización distinta: Q4_K_M vs Q6_K. La cuantización más agresiva podría paradójicamente mejorar la decisión del modelo en ciertos aspectos, o la diferencia podría ser neutral o negativa en otros.
- Mejoras del entrenamiento de Wan 2.2: El modelo podría simplemente estar mejor entrenado, independientemente de la arquitectura.
Sin pruebas de ablación (ejecutar Wan 2.2 con Q6_K, o Wan 2.1 con dos modelos ficticios, etc.), no puedo separar estas variables. Lo que sí sé es que el resultado final es visiblemente mejor en esta configuración específica.
Preguntas frecuentes
P: ¿Qué diferencia arquitectónica tiene Wan 2.2 respecto a Wan 2.1?
R: Wan 2.2 usa un diseño de mixture-of-experts (MoE) con dos modelos separados de 14B: un modelo ‘HighNoise’ para los primeros pasos de denoising y un modelo ‘LowNoise’ para los últimos pasos de refinamiento, encadenados vía dos nodos KSamplerAdvanced. Wan 2.1 usa un único modelo unificado.
P: ¿Wan 2.2 I2V tiene mejor calidad que Wan 2.1 I2V?
R: En esta prueba concreta (mismo frame, misma semilla), sí — claramente. El saco de boxeo se mantuvo nítido y bien definido en todos los frames de la salida de Wan 2.2, frente al ablandamiento visible en la de Wan 2.1. La prueba no aisló si esto vino de la nueva arquitectura MoE, de la cuantización distinta usada, o de mejoras generales del modelo.
P: ¿Wan 2.2 I2V es más lento que Wan 2.1 al usar dos modelos?
R: No, de hecho fue más rápido en esta prueba: 18 minutos 3 segundos frente a los 20 minutos 10 segundos de Wan 2.1, pese a correr dos modelos de 14B en vez de uno. Los modelos se cargan dinámicamente uno a la vez en vez de estar residentes simultáneamente.
P: ¿Necesito dos modelos de 14B para Wan 2.2 I2V en ComfyUI?
R: Sí, la arquitectura MoE requiere ambos. Sin embargo, no necesitas que residan simultáneamente en VRAM gracias a la carga dinámica. ComfyUI carga HighNoise, lo usa, lo descarga, carga LowNoise, lo usa. En una RTX 3090 de 24GB, Q4_K_M funciona. En tarjetas más pequeñas, podrías necesitar cuantización más agresiva (Q3_K_M o Q2_K), con pérdida de calidad.
P: ¿Qué cuantización debo elegir para Wan 2.2 GGUF?
R: Q4_K_M es un buen punto de equilibrio en 24GB. Q6_K ofrece mejor calidad pero necesita más VRAM (probablemente 28GB+). Q3_K_M comprime más pero sacrifica detalles. Depende de tu tarjeta y de cuánto te importe la calidad vs. velocidad.
P: ¿Puedo usar el VAE de Wan 2.1 con Wan 2.2?
R: Sí, y eso es lo que hace el template oficial. Wan 2.2 reutiliza el VAE de Wan 2.1 sin cambios. Esto reduce la complejidad de la configuración.
Sigue leyendo
Si quieres ver la prueba con Wan 2.1 con la que comparamos este resultado, consulta nuestro artículo de Wan 2.1 I2V con el mismo frame de partida. Para la fuente original de texto-a-vídeo, revisa nuestra guía de LTXV-2.3 + RTX Super Resolution. Y si las cuantizaciones GGUF no te resultan familiares, nuestra guía de GGUF en ComfyUI explica los trade-offs.
🏆 Nuestra recomendación
Si tienes una RTX 3090 o mejor y buscas máxima calidad visual en generación de video local: Elige Wan 2.2 I2V. En esta prueba controlada dio resultados visiblemente superiores en definición y movimiento, además de ser más rápido que Wan 2.1 — aunque no se puede afirmar con certeza que sea específicamente la arquitectura MoE la responsable, y no la cuantización distinta.
Si tu tarjeta tiene menos de 24GB de VRAM o priorizas velocidad extrema: Considera Wan 2.1 I2V o espera a pruebas con el LoRA lightx2v de Wan 2.2, que promete 4 pasos en lugar de 20.
Si quieres ir más allá: Descarga los GGUF Q4_K_M de QuantStack, usa el template oficial de ComfyUI, y prueba Wan 2.2 I2V con tu propio primer frame. La generación de video local está mejorando rápido, y cada arquitectura nueva nos acerca más a resultados que hace un año hubieran requerido GPU de $10k.
Conclusión
Wan 2.2 I2V no es solo una actualización de números: el cambio a mixture-of-experts con dos modelos especializados es un cambio arquitectónico real. En esta prueba controlada, la salida de Wan 2.2 tuvo más definición, movimientos más decididos y menos deriva de forma que Wan 2.1, además de completarse más rápido pese a la complejidad añadida. Lo que no puedo afirmar con los datos de esta única prueba es que la arquitectura MoE en sí sea la causa — la cuantización distinta usada en cada prueba (Q4_K_M aquí, Q6_K en Wan 2.1) es una variable que no se aisló.
Si estás generando video local en ComfyUI y tienes una RTX 3090 o mejor, vale la pena probar Wan 2.2 I2V. Descarga los GGUF Q4_K_M de QuantStack, usa el template oficial, y espera una mejora tangible sobre Wan 2.1. Si tu tarjeta tiene menos VRAM, planifica la cuantización cuidadosamente. Y si quieres ir más rápido aún, el LoRA lightx2v está ahí esperando su propia prueba.
¿Tienes una RTX 3090 o similar? Prueba Wan 2.2 I2V con tu propio primer frame y comparte qué diferencias ves en los comentarios. La generación de video local está mejorando rápido, y cada arquitectura nueva nos acerca más a resultados profesionales sin depender de servicios en la nube.
Siguientes pasos en ComfyUI
Primeros pasos
Preguntas frecuentes
- ¿Qué diferencia arquitectónica tiene Wan 2.2 respecto a Wan 2.1?
- Wan 2.2 usa un diseño de mixture-of-experts (MoE) con dos modelos separados de 14B: un modelo 'HighNoise' para los primeros pasos de denoising y un modelo 'LowNoise' para los últimos pasos de refinamiento, encadenados vía dos nodos KSamplerAdvanced. Wan 2.1 usa un único modelo unificado.
- ¿Wan 2.2 I2V tiene mejor calidad que Wan 2.1 I2V?
- En esta prueba concreta (mismo frame, misma semilla), sí -- claramente. El saco de boxeo se mantuvo nítido y bien definido en todos los frames de la salida de Wan 2.2, frente al ablandamiento visible en la de Wan 2.1. La prueba no aisló si esto vino de la nueva arquitectura MoE, de la cuantización distinta usada, o de mejoras generales del modelo.
- ¿Wan 2.2 I2V es más lento que Wan 2.1 al usar dos modelos?
- No, de hecho fue más rápido en esta prueba: 18 minutos 3 segundos frente a los 20 minutos 10 segundos de Wan 2.1, pese a correr dos modelos de 14B en vez de uno. Los modelos se cargan dinámicamente uno a la vez en vez de estar residentes simultáneamente.


